Search Engine
Introduction
Web search in principle is divided into 3 phases: 1) The web crawler where most of the data is retrieved by crawling through the webpages 2) The next is indexing where we index the data collected from crawling 3) Lastly frontend where we display the results. The languages used for the each phase are: Phase 1: Crawler was implemented in python Phase 2: Lucene indexing was implemented in Java Phase 3: The frontend was implemented in HTML, CSS, and JavaScript.
Web crawler
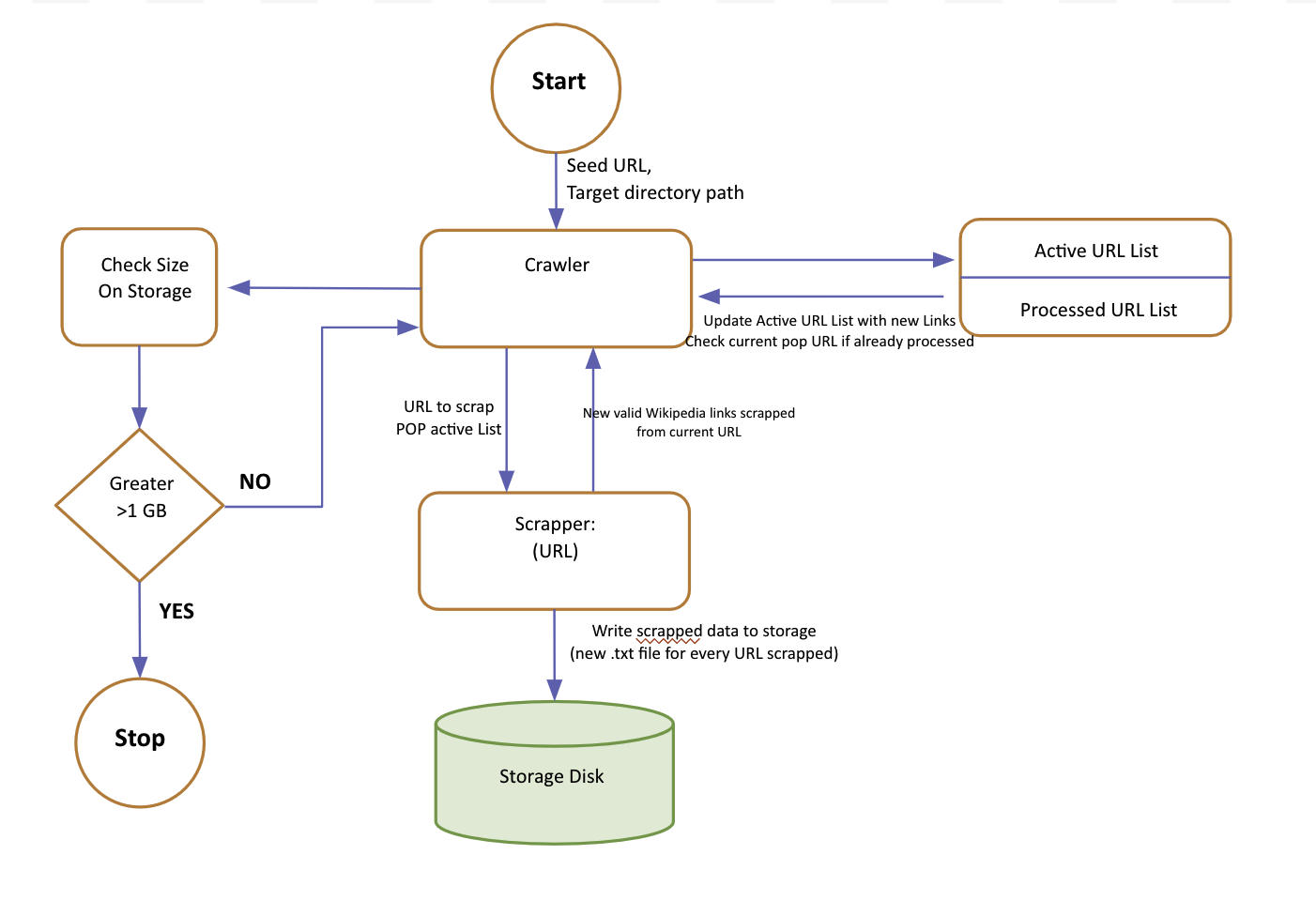
The overall high-level design of the Crawling System can be viewed as the following flow diagram:
Crawling strategy
We have implemented the depth first search technique. We take the root link as input and extract all the textual data from the web page and then we add all the hyperlinks from that page to the queue data structure. As soon as the link is processed, we pop it from the queue and append all the hyperlinks in the queue. We follow the FIFO (First in First Out) method to pop out the processed queue. Similarly, we process all the hyperlinks in the queue and extract the data and their corresponding hyperlinks and append in the queue.
We use try and catch error block in order to skip the broken links which interrupt the flow of our program. The program skips these links and pops the other link from the queue in order to process them. The crawled data is then stored in the local file in the excel sheets. You can find the code here.
Issues faced during crawling
- How to handle duplicate pages? We use the ordered set data structure because a set does not allow duplicate values. We pass the activeLinklist (ordered set) to the getuniquelinks() function to process the duplicate pages and then we return it.
- How to crawl the data efficiently? By using multiprocessing and multithreading for every seed url and separate instance of the crawler class is initialized and inside all instances multiple threads are running (of order 40 to 50) to use the down time between the file I/O and retrieving the html data from each site.
- How to handle the links which does not permit crawling? In order to handle this, we used the filter function from Python and filtered out the links containing various punctuation marks and braces on their tail ends.
- Repeated links appear which crawling and the crawler sometimes crawls the same page and does not updated after the previous crawl. This results in an infinite loop of crawling. This issue is addressed by letting the crawler crawl 1 GB of data hy simultaneously checking if the page has been crawled before. We use DFS approach to retrieve each of these webpages
Indexing
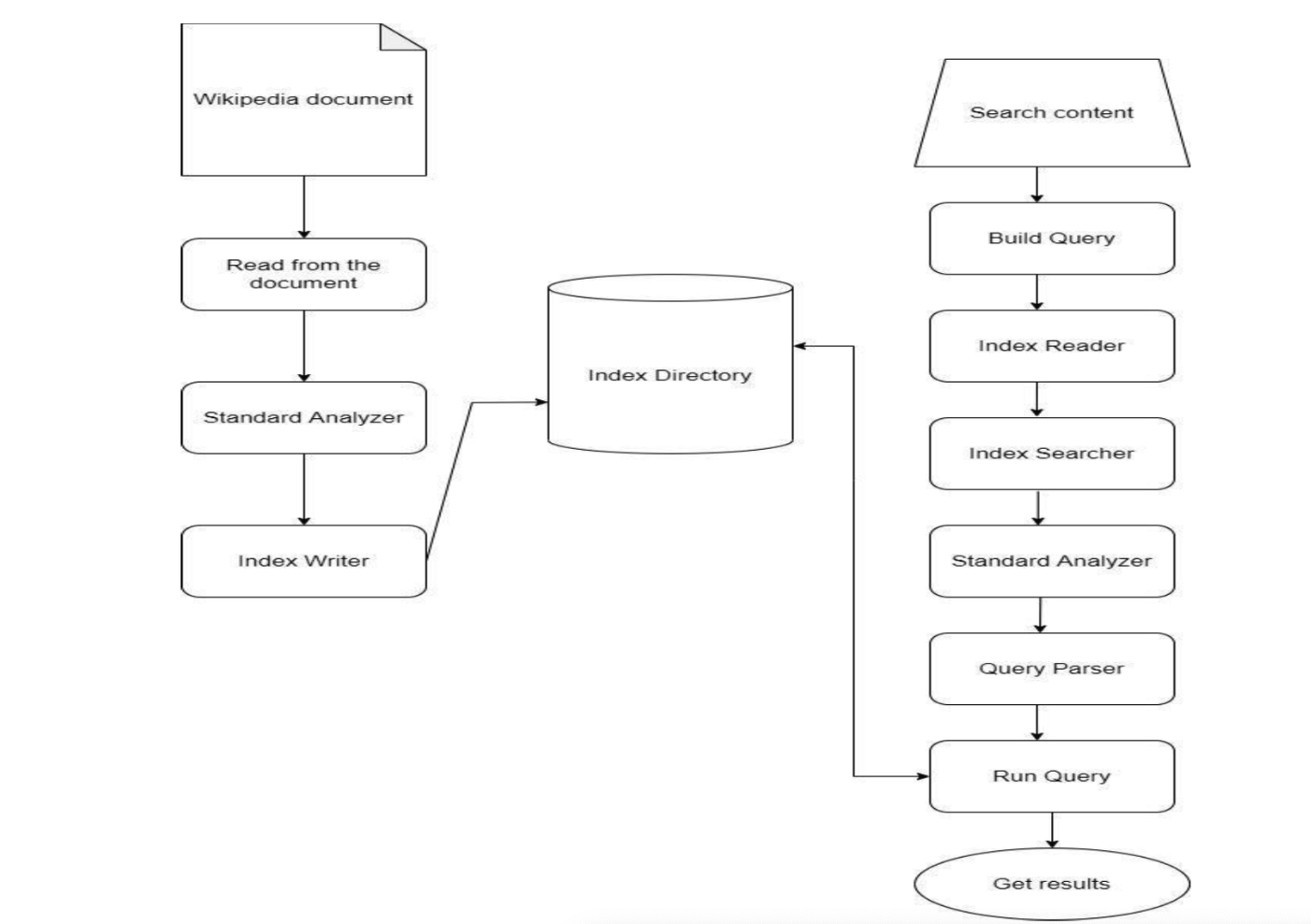
Strategy
- The dataset consisting of Wiki documents is read in the first step.
- We use a Standard Analyzer to analyze the document. This examines the text of fields and generates a token stream.
- Then we create an object of the Index Writer.
- After that, a Lucene directory is created where the indexes are stored.
- To search a query, we first build a query.
- Then an Index Reader, Index Searcher, and the Standard Analyzer are used.
- We use the Query Parser which interprets a string into a Lucene query.
- Finally, the query is run and the results are obtained. You can find the code here.
Lucene Fields
- String Field: String field is a type of field that can be indexed but cannot be tokenized. When indexing is done, the entire string value is being indexed as a single token. This field has a limitation of 255 characters.
- Text Field: This field can be indexed and is tokenizable. This is used without the term vectors. This can be used on most of the document’s texts such as the body field. This field has a limitation of 30000 characters.
Lucene Analyzer
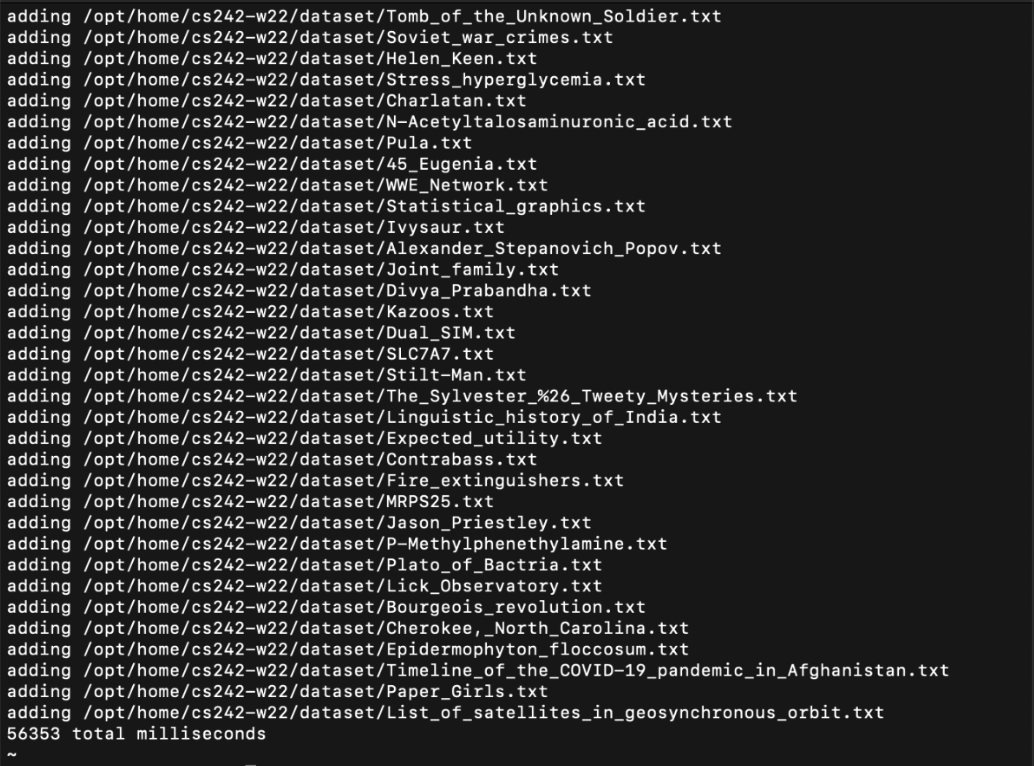
The analyzer is responsible for the processing of the strings which occurs during indexing and execution of queries. We have used only one analyzer, the Standard Analyzer which can easily recognize the URLs that are essential for our project implementation. It can break the text into elements that follow the Unicode Text Segmentation norm. We don’t require any specification or configuration to implement the analyzer. It can also remove stop words and has the ability to change the generated tokens into lower case. it takes 56353 milliseconds to index the files.
Results
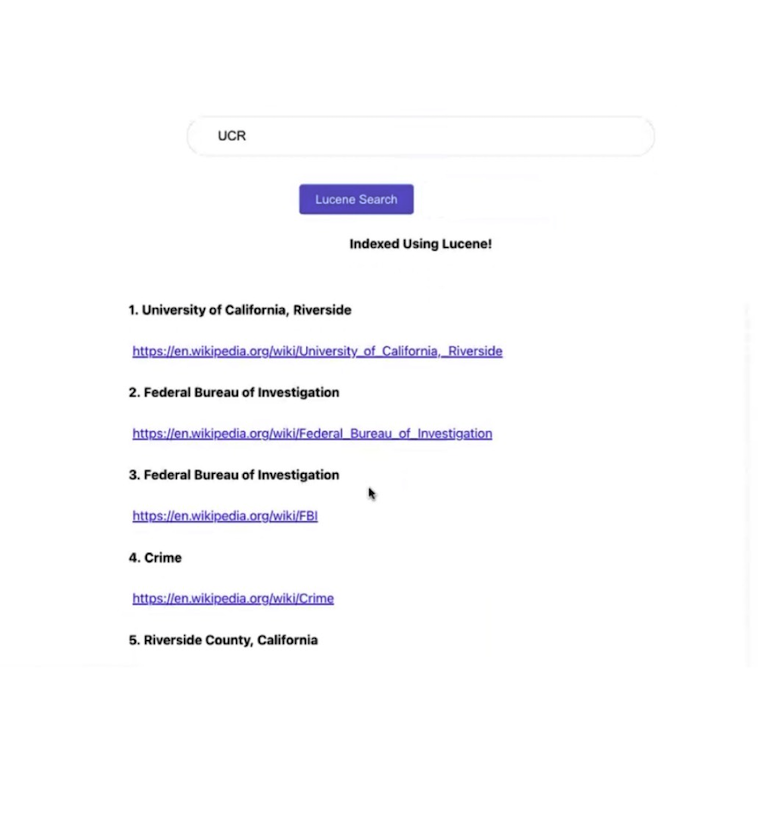
Results of search query: Riverside
Frontend (Web User Interface)
To create the frontend of our search engine we have used HTML, CSS, and JavaScript. The layout of the web page is like that of Google. There is a button used for Lucene searching. It displays the top 20 ranks, heading and URL of the Wikipedia pages based on the search query.
Lucene Search
This shows the results based on Lucene indexing. There are 20 results displayed based on the search query. The parameters shown in the result are link, rank and heading. The link is the URL shown in anchor tag so that the user can click to show the corresponding web page. Rank shows the rank of the ranking of the result. The heading shows the name of the result which is the corresponding web page. The rank and heading are shown in bold. This shows the results instantaneously. You can find the code here.
Results